
I’m really sorry for how late this is! I’ve been in Colorado and am now going to Texas to look at graduate schools (I’m writing to you from the airport on a borrowed computer). Unfortunately, my computer stopped working my first night in Colorado, and I have not been able to update my blog until now. I have been working on my capstone some, and am planning to finish most of it up by the end of the weekend. Thus far, it is closely resembling my outline (available in my Week 6 post). While visiting the Colorado School of Mines in Golden, CO I was able to speak with the writer of one of my main sources, Dr. William Navidi. Dr. Navidi is a statistician at CSM, and I mentioned to him that I was using one of his texts as a main source for my capstone, and he was very happy to know that his work was being used. Aside from that, I do not have anything interesting or new to report. Good luck to all on their capstone work.
My capstone outline can be viewed at this URL
First, I’m sorry again for this late post, I completely forgot to do this on Friday (I’ve been quite busy). In any case, here is an update of my outline progress. So far, I have only written an introduction portion for my outline. In my introduction, I briefly explain what case control studies are, why they are used, and introduce some vocabulary used in the study of case control studies, such as odds ratios, cohorts, etc. I will also talk about some alternatives to case control methods, such as multinomial methods and cohort sampling.
In the next sections, I will explain some of the assumptions of a case control study, and why they’re important. For instance, the assumption that the disease/condition under consideration is rare means that odds ratios will more closely approximate risk ratios. Risk ratios are a more direct measure of the likelihood of getting a disease given exposure to a certain factor, but odds ratios are easier to calculate.
In the mathematically rigorous sections, I will describe how the logistic model is related to case-control sampling, and how it is used to estimate odds ratios. I have not yet articulated how this will find its way into my outline, but it will. In any case, my outline will be complete and ready to be turned in by Friday.
This week was not very productive in terms of working on my math capstone. In my defense, my first draft for my biology capstone is due Monday 3/7, and has been receiving most of my attention this week. I did work on my math capstone to the extent that I have been in contact with Dr. Munson (my capstone adviser) who has been pointing me towards some useful resources. One of these resources is a basic summary of Case-Control Methods written by Dr. William Navidi at the Colorado School of Mines. This will be an extremely useful guide for writing my capstone, because it describes the more mathematically rigorous aspects of case control studies. It carefully describes what I had described in my last post. That is, it describes the process by which a distribution is selected for odds ratios. The logistic distribution is selected because it maintains probabilities within the range of [0,1] while other distributions and models could predict probabilities greater than 1, which would not make mathematical sense. In the coming week (when the draft of my biology capstone will be complete), I will continue to read Dr. Navidi’s guide, as well as write my outline, which at this point I intend to structure in the manner that was described in my previous post.
This past week, I spent a lot of time formalizing what I would like to say about the background information of case control studies, and began to think about the subsequent sections of my capstone. As a rough outline of my capstone, I will include background information about case-contorl studies, and then a discussion of maximum likelihood and how it relates to case control studies. In my background information section, I will talk about what case-control studies are, and some of their strengths and weaknesses. I will also discuss some of the terminology surrounding case control studies, such as risk, relative risk, odds, and odds ratio, and explain some of the properties of these terms. I will then provide a general background discussion about maximum likelihood functions, and how they are obtained, and how parameters can be maximized as functions of the data.
Then, I will state that data from case-control studies tend to follow the Logistic Model Distribution. Using the probability density function of this distribution, I will then be able to show what the likelihood function would look like, and subsequently, how one would go about maximizing the likelihood function. The maximum estimate of the parameter of interest, namely the extent to which exposure to some factor increases the likelihood of disease (or non disease), can then be used to draw conclusions about case-control studies.
This week, I read some more about case-control studies from an Epidemiology text. Having had a full semester of statistics, I am understanding more and more of the text than I did when I first started reading it last semester. Furthermore, in Math348 (Regression Analysis and ANOVA) this past week we discussed likelihood functions and maximum likelihood functions, which can be applied to case control studies. The likelihood function is derived from the probability density function (which is hard to come by, evidently and so sometimes assumptions of the underlying distribution must be made). The probability density function is a function of the parameters, and tells you the probability of observing certain outcomes. To my understanding, the likelihood function is the same function as the probability density function, but instead is a function of outcomes, and tells you how likely certain parameters are. The maximum likelihood function utilizes the tools of calculus to find the most likely parameters given the observed data. These are applicable to case control studies in that parameters, such as the probability that one gets skin cancer, can be estimated from the data obtained by case control studies.
In the upcoming week, I will continue to read my text, and several scholarly articles and take systematic notes on their content and material. I will also meet with my capstone adviser (who was sick for most of this week). My goals last week (to possibly draft an introductory section) were a little too ambitious, but I will at least try to work on one in the coming week.
Sorry for the lateness of this post, I completely forgot to update. Over J-term and J-term break, I had plans to work on my capstone, but they largely fell through. I read one of my books several times at night, but usually fell asleep within 15 minutes of beginning to read it. Fortunately, I got a lot done of my biology capstone. In particular, I got lots of practice with public speaking and making slide shows which will help me with my math capstone presentation. I also saw other people present their capstones, and now have an idea of what it means to present a slide show well as well as what it means to present a slide show poorly.
This week, I will sit down with several of my books (not at night) and systematically read them and take notes, and perhaps draft an introduction section to my paper. I have an adequate idea of what case control studies are and why they’re important, but I need to read more about them so that I can better articulate my thoughts about them. Furthermore, I need to find more mathematically rigorous content that I can incorporate into my capstone. I have a basic notion of what I would want to cover in my outline as well: 1) introduction to case-control studies (including history), 2) mathematics of case-control studies (fairly vague for now, but this is where I intend to incorporate the mathematically rigorous aspects), and 3) an example of a real-life case-control study.
In class, we went over an interesting derivation for one of the coefficients, 













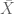


In my capstone, I will likely be talking about odds ratios. Odds ratios are summary statistics which help to describe the association between two variables. For instance, in my capstone, I showed how an odds ratio can be used to show that there is a link between the use of sunscreen and decreasing one’s chances of getting skin cancer. An odds ratio is the ratio of the probability that an event occurs (for instance, getting skin cancer) in one group (for instance, people who use sun screen) to the probability that that same event occurs in another group (for instance, people who don’t use sun screen). Naturally, an odds ratio less than one indicates that the event is less likely to occur in the first group, and an odds ratio greater than one implies that the event is more likely to occur in one group. An odds ratio equal to 1 is inconclusive, and an odds ratio equal to zero is undefined (and has no meaning).
Many standard statistical tools can be applied to odds ratios, as they are just a summary statistic. Often times, the odds ratio is converted to the log-odds ratio, because they are generally easier to work with (logarithm rules help to simplify calculations, etc.). For instance, it can be shown that the standard error associated with a log odds ratio calculation is 

I remember hearing about the Traveling Salesman Problem from my dad (who is a computer programmer) when I was younger, and wondering what the big deal was about the problem. The problem states that a salesman must visit n cities during a business trip, and must find the shortest possible route he could take such that he visits all of the cities. This problem is directly applicable to logistics problems such as finding the most optimal way to deliver packages to peoples’ homes. With some slight modifications, this process can be applied to DNA sequencing. Sometimes, when trying to sequence a genome, a genome can be randomly broken apart (usually by a process called sonication), and have these individual fragments be sequenced individually (because sequencing smaller fragments is feasible, while bigger fragments are much harder to sequence). The sequences must then be reassembled (which is done by coupling regions with overlapping sequences). This reassembly process is (or at least can be) an application of the traveling salesman problem.
The mathematics of this problem are fairly complex (at least they appear to be on Wikipedia), so I will not try to get into them. Rather, I will state that this problem is a good example of how some thought exercises can be good model systems for real-life problems. Coincidentally, this problem is directly applicable (logistics, etc.) but there are many “thought exercises” whose applications aren’t apparent. For instance, the Weierstrass Function is continuous everywhere, but differentiable nowhere. While it does not have any direct application (not to my knowledge, at least), the fact that such a function exists could serve as the basis for many developments in analysis.
